1.基本概念
简介
聚类是一种无监督学习的机器学习技术,它旨在将数据集中的对象分成几个相似的组,每个组通常被称为一个簇,以便簇内的对象之间具有高度相似性,而不同簇之间的对象具有较低的相似性。聚类的目标是根据数据的内在结构,将相似的数据点聚集在一起,以便识别模式、发现隐藏的结构以及实现数据的压缩和汇总。
聚类分析的目标是,组内的对象相互之间是相似的,而不同组中的对象是不相似的,组内的相似性越大,组间的差别越大,聚类就越好。
1.1一个简单的例子
当我们将鱼塘中的鱼按其相似性进行分组,这个过程就是聚类。种类的相似性或者颜色的相似性都可以作为相似性度量的方法。在一般的聚类算法中,我们常用欧氏距离、曼哈顿距离、余弦相似性等方法来度量。
1.2 不同的聚类类型
-
层次的与划分的
- 划分聚类就是简单的将数据对象集划分为不重叠的簇,下图中b,c,d都是一个划分聚类
- 层次聚类是嵌套簇的集族,组织成一棵树。层次聚类可以看做划分聚类的序列。下图中(a~d)显示的簇依次形成一个层次聚类,每层分别有1,2,4,6个簇。

-
互斥的、重叠的、模糊的
- 互斥的:每个对象都指派到单个簇
- 重叠的:一个对象可指派到多个簇,例如,在大学里,一个人可能既是学生又是雇员。
- 模糊的:每个对象以一个0到1之间的隶属权值属于每个簇。
-
完全的与部分的
- 完全聚类中每个对象都会被指派到一个簇中
- 部分聚类存在未指派簇的对象
1.3 不同的簇类型
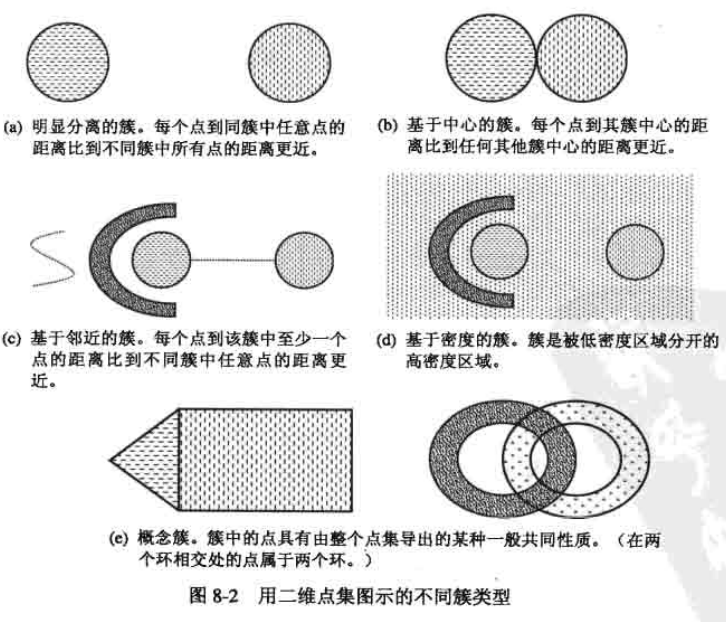
- 1)明显分离的:图a中显示的就是明显分离的簇的例子,不同组中的任意两点之间的距离都大于组内任意两点的距离。明显分离的簇不必是球形的,可以具有任意形状。
- 2)基于原型的:簇内对象到定义该簇的原型的距离比到其他簇的原型的距离更近。通常把基于原型的簇看作基于中心的簇,一般这种簇趋近球形。
- 3)基于图的: 如果数据点作为图的节点,边代表数据对象之间的联系来构成一个图,那么簇就可以定义为连通分支,连通的一组数据点可以指派到一个簇。
- 4)基于密度的:簇是对象的稠密区域,被低密度的区域环绕。
- 5)概念簇:概念簇的基本思想是将相关的概念或主题归为一组,从而形成一个聚类,以帮助用户更容易找到相关信息或了解数据的结构。
2.几种经典的聚类算法的实现
2.1.基本的K均值算法(KMeans)
K均值是基于原型的、划分的聚类技术。
基本算法: 随机选择K个初始质心,其中K是用户指定的参数,即所期望簇的个数,然后将所有的数据点指派到距离最近的质心的簇。指派完后根据簇中的点更新每个簇的质心。重复指派和更新步骤,直到簇不发生变化。
伪代码:

Python代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
"""
k-Means聚类算法,返回最终的k各质心和点的分配结果
"""
m = dataSet.shape[0] # 获取样本数量
# 构建一个簇分配结果矩阵,共两列,第一列为样本所属的簇类值,第二列为样本到簇质心的误差
clusterAssment = np.mat(np.zeros((m, 2)))
# 1. 初始化k个质心
centroids = createCent(dataSet, k)
clusterChanged = True
while clusterChanged:
clusterChanged = False
for i in range(m):
minDist = np.inf
minIndex = -1
# 2. 找出最近的质心
for j in range(k):
distJI = distMeas(centroids[j, :], dataSet[i, :])
if distJI < minDist:
minDist = distJI
minIndex = j
# 3. 更新每一行样本所属的簇
if clusterAssment[i, 0] != minIndex:
clusterChanged = True
clusterAssment[i, :] = minIndex, minDist ** 2
print(centroids) # 打印质心
# 4. 更新质心
for cent in range(k):
ptsClust = dataSet[np.nonzero(clusterAssment[:, 0].A == cent)[0]] # 获取给定簇的所有点
centroids[cent, :] = np.mean(ptsClust, axis=0) # 沿矩阵列的方向求均值
return centroids, clusterAssment
|
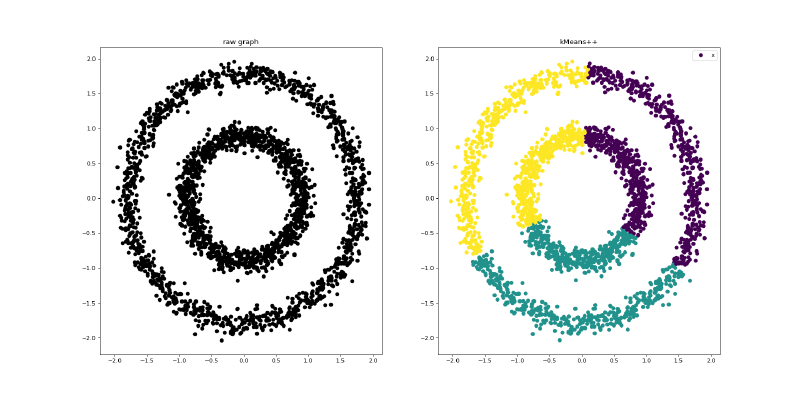
运行示例
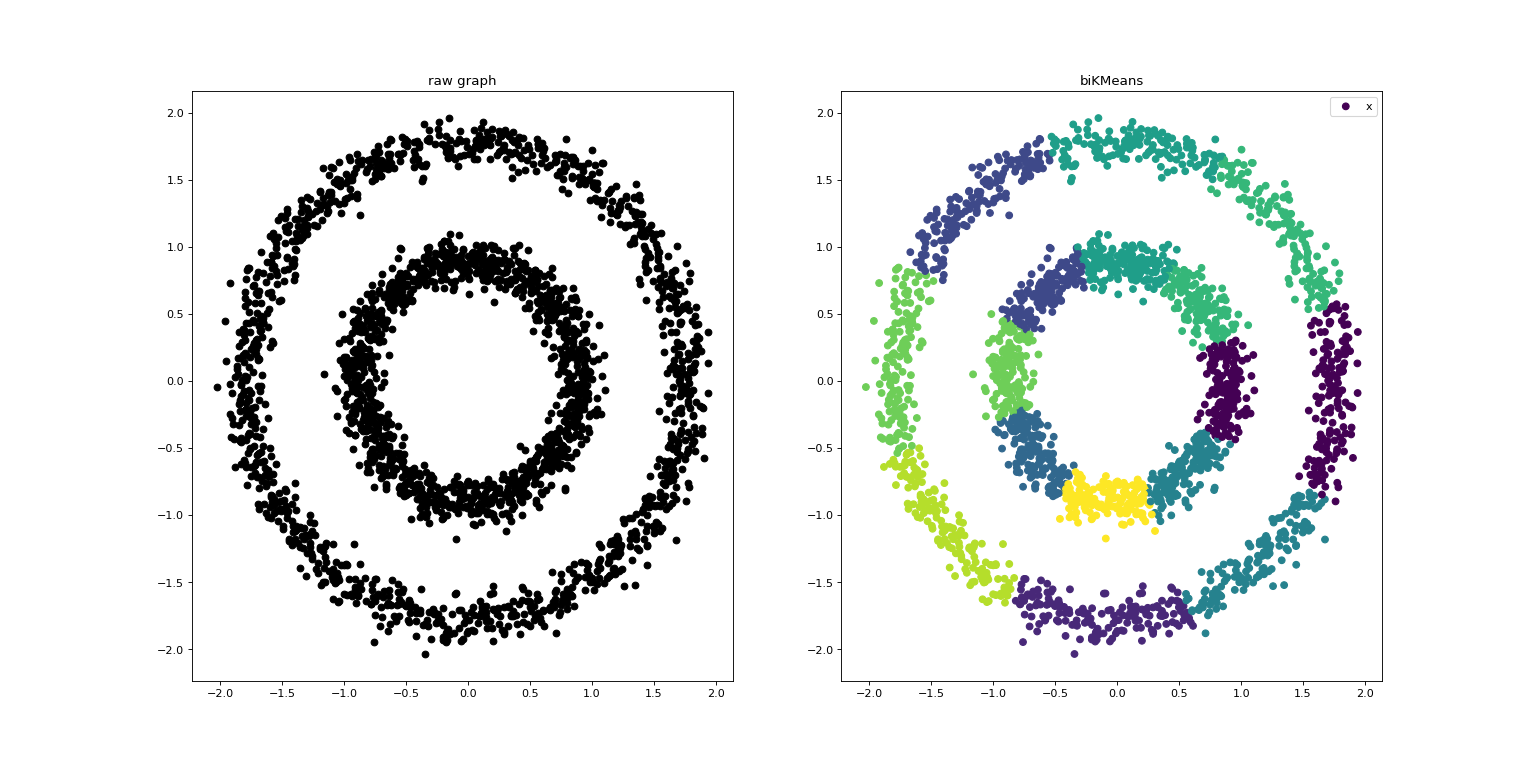
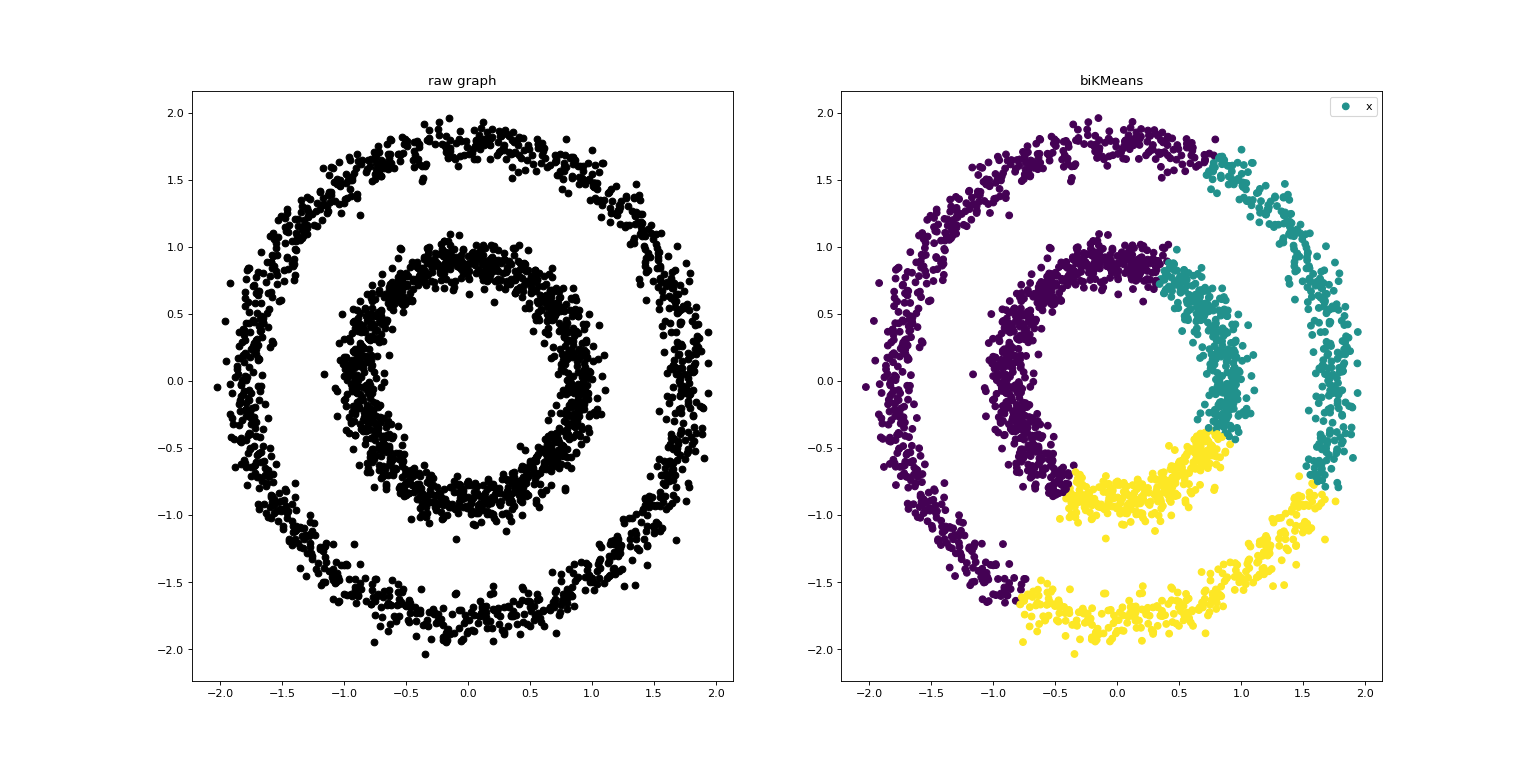
2.2.二分K均值算法(biKMeans)
二分K均值算法是K均值算法的直接扩充,是基于一种简单的想法:为了得到K个簇,将所有的点的集合作为初始簇,然后分裂成两个簇,从这些簇中选取一个簇进行分裂,重复选取和分裂,直到产生K个簇。
伪代码

待分裂的簇有许多种不同的选择方法,可以选择最大的簇,或者最大SSE的簇,或者使用一个基于大小和SSE的标准进行选择。不同的选择将导致不同的簇。
SSE介绍


biKMean代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
def biKMeans(dataSet, k, distMeas=distEclud):
"""
二分k-Means聚类算法,返回最终各点的分配结果
"""
m = dataSet.shape[0] # 获取样本数量
# 构建一个簇分配结果矩阵,共两列,第一列为样本所属的簇类值,第二列为样本到簇质心的误差
clusterAssment = np.mat(np.zeros((m, 2)))
n = dataSet.shape[1] # 获取数据的维度
centroids = np.mat(np.zeros((k, n)))
centroids[0, :] = np.mean(dataSet[:, :], axis=0) # 初始簇的质心
for i in range(m): # 计算初始簇样本到簇质心的误差
clusterAssment[i, 1] = distMeas(centroids[0, :], dataSet[i, :]) ** 2
new_cluster_label = 1
# 每次分裂生成一个新簇,分裂K-1次完成
while new_cluster_label < k:
largest_sse_cluster_label = -1
largest_sse = -1
# 找到现有簇中最大sse的簇
for cluster in range(new_cluster_label):
cluster_sse = sum(clusterAssment[np.nonzero(clusterAssment[:, 0].A == cluster)[0], 1])
if cluster_sse > largest_sse:
largest_sse_cluster_label = cluster
largest_sse = cluster_sse
# 将最大sse的簇进行多次分裂(3次),选择最小总sse的两个簇
cluster_data_indexs = np.nonzero(clusterAssment[:, 0].A == largest_sse_cluster_label)[0]
largest_sse_cluster = dataSet[cluster_data_indexs]
lowest_sse = np.inf
for j in range(3):
sub_centroids, sub_clusterAssment = kMeans(largest_sse_cluster, 2, distMeas=distMeas)
tol_subClusters_sse = sum(sub_clusterAssment[:, 1])
if tol_subClusters_sse < lowest_sse:
best_newCentroids = sub_centroids
best_assment = sub_clusterAssment
lowest_sse = tol_subClusters_sse
# 更新质心
centroids[new_cluster_label - 1, :] = best_newCentroids[0, :]
centroids[new_cluster_label, :] = best_newCentroids[1, :]
# 更新簇分配矩阵,子簇类别为0,分为原簇标签,子簇类别为1,则新分配一个类别
for i in range(len(cluster_data_indexs)):
sub_cluster_label = best_assment[i, 0]
clusterAssment[cluster_data_indexs[i], :] = largest_sse_cluster_label if sub_cluster_label == 0 else new_cluster_label, best_assment[i, 1]
# 下一个新分配的簇标签
new_cluster_label += 1
return clusterAssment[:, 0].A[:, 0]
|
二分K均值(Bisecting K-Means)是对基本的K均值算法的一种改进,其主要提升在于以下几个方面:
- 初始簇的选择更合理:在二分K均值中,一开始将整个数据集视为一个簇,然后通过反复的二分操作,将数据集一分为二,以生成两个初始簇。这有助于更合理地选择初始簇,减少了对初始质心的敏感性。
- 减少局部最小值问题:由于二分K均值从整个数据集开始,而不是一个随机初始簇,它更有可能避免陷入局部最小值问题,即更有可能找到更优的簇划分。
- 更均匀的簇大小:通过反复的二分,二分K均值可以生成具有相对均匀大小的簇,而不同于基本K均值,可能出现某些簇特别大或特别小的情况。
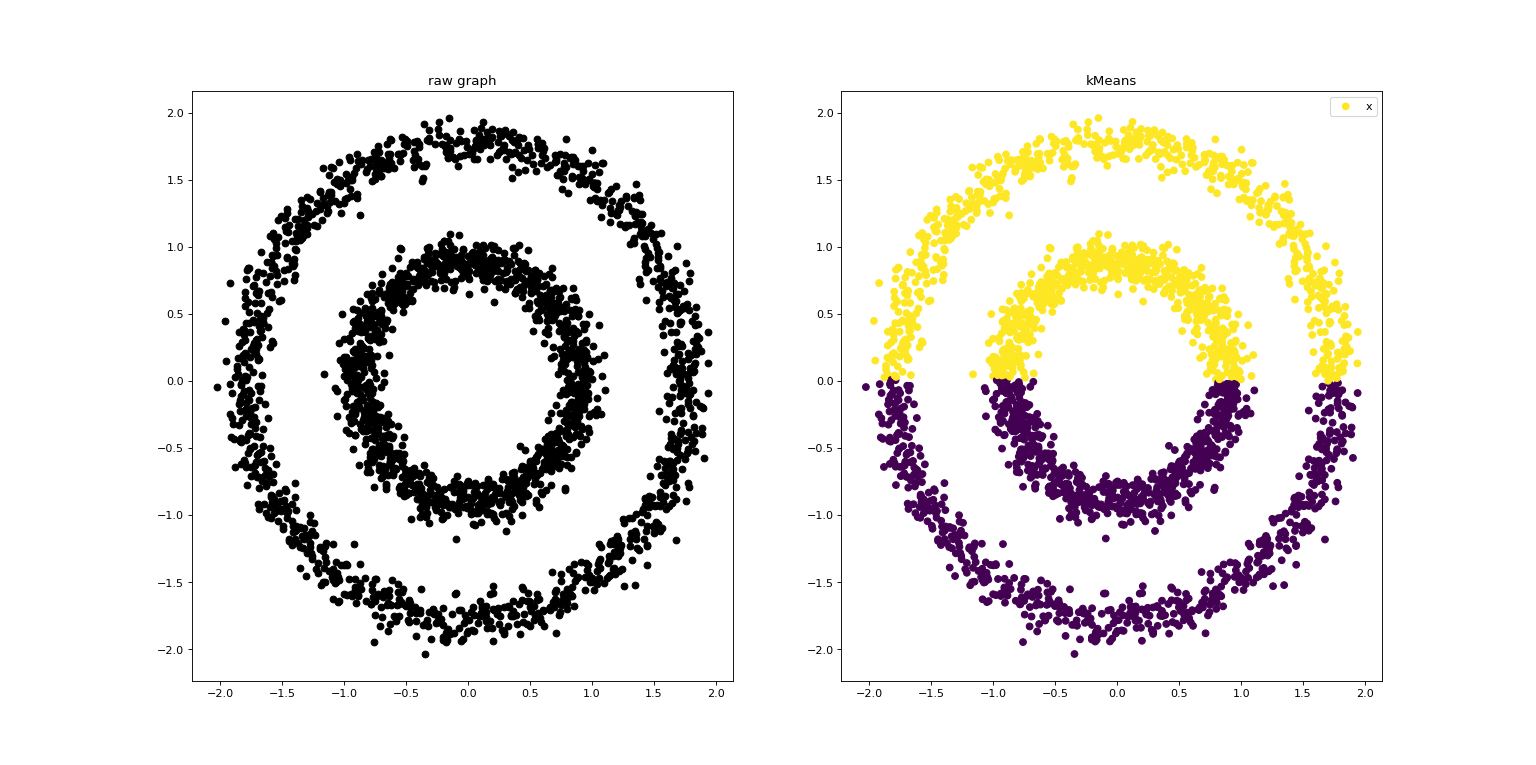
运行示例:
2.3.KMeans++算法的实现
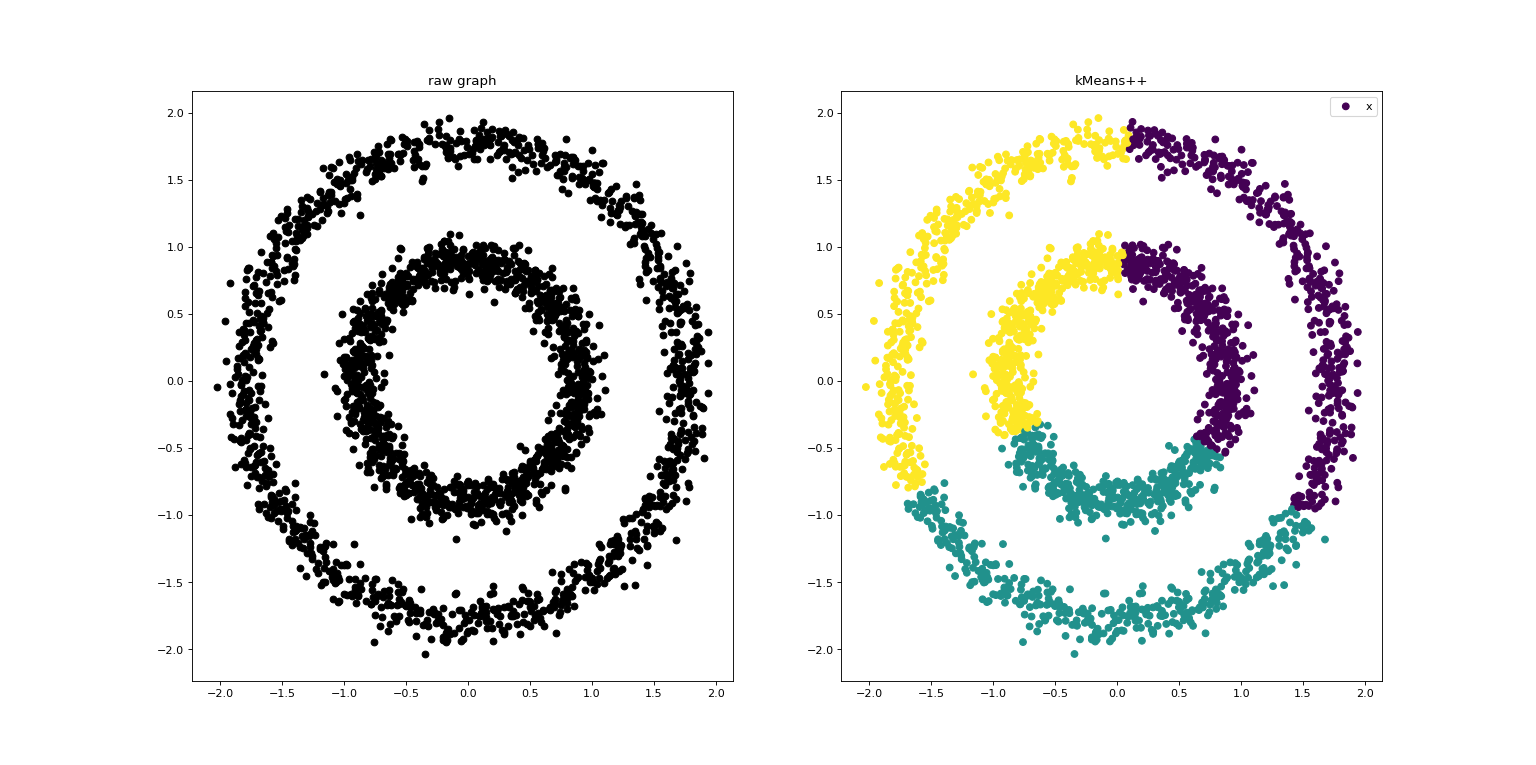
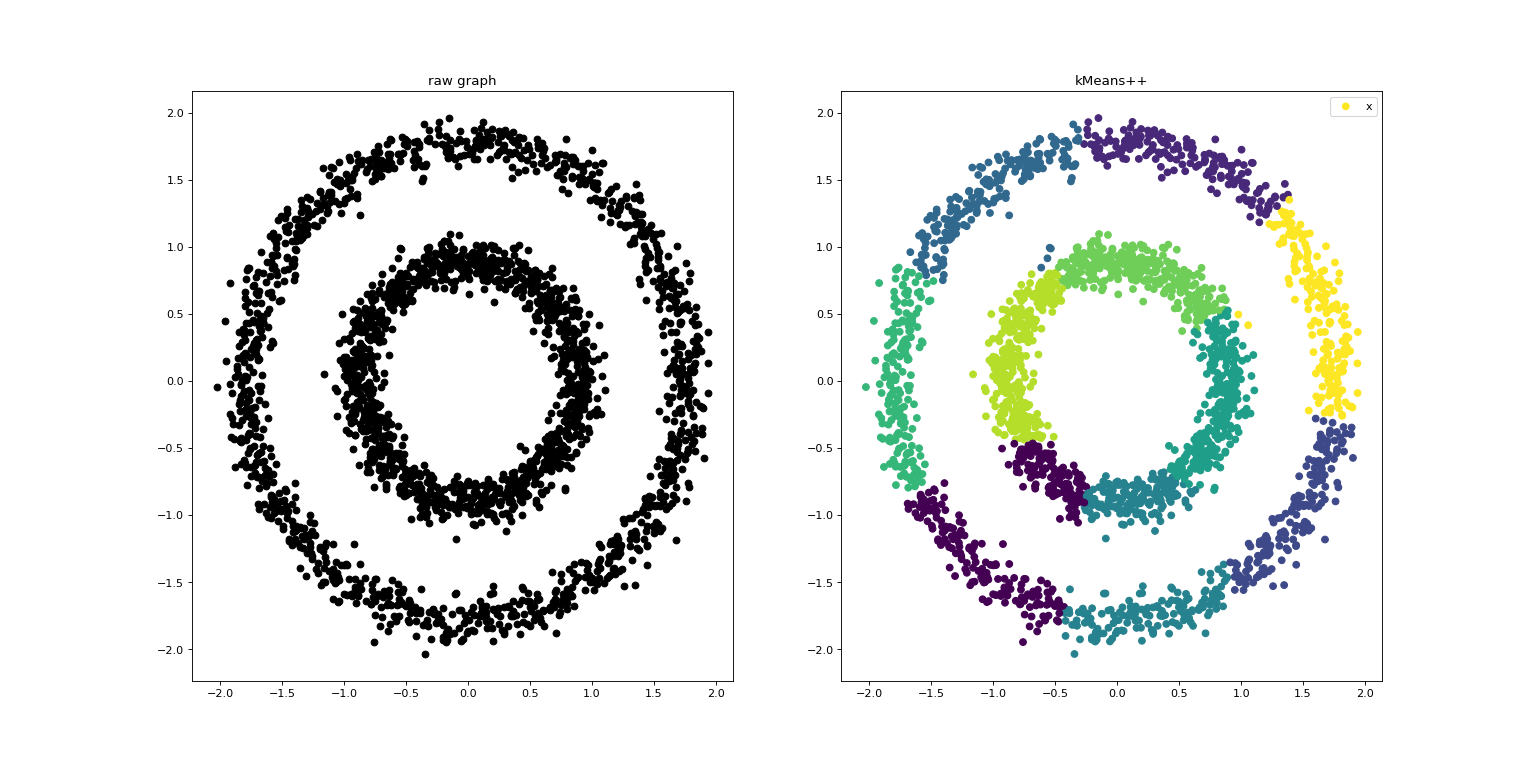
KMeans是质心敏感的聚类算法,其初始质心的选择是随机的。
K-Means++ 采用了一种智能化的方法来选择初始的簇中心,而不是随机选择。它通过权衡距离数据点较远的中心,减少了初始簇中心的偶然性。这有助于减少 K-Means 算法陷入局部最小值的风险,从而提高了算法的收敛性和稳定性。
KMeans++对基本K均值算法的改进就是体现在初始K个质心的选择上。剩下的步骤和基本K均值算法一致。
伪代码:
首先随机选择一个初始质心,然后迭代地选择剩余的K-1个质心,确保这些质心相对分散,以减少陷入局部最小值的可能性。它遍历每个数据点,为每个数据点找到到当前所有质心中最近质心的距离,然后选择离最近质心距离最大的数据点作为新的质心,加入存放质心的数组。不断重复,最终函数最终返回K个初始化的质心。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
def kpp_initialize(dataSet, k):
"""
用于K-Means++的初始化质心
"""
# 从数据点中随机选择第一个质心
centroids = [dataSet[np.random.choice(dataSet.shape[0])]]
# 选择剩下的k-1个质心
for i in range(k - 1):
dist = []
for j in range(dataSet.shape[0]): # 遍历每个点找到离现有质心最近距离的最大的点
min_dist = sys.maxsize
for cent in range(len(centroids)):
temp_dist = distEclud(centroids[cent], dataSet[j, :])
min_dist = min(min_dist, temp_dist)
dist.append(min_dist)
dist = np.array(dist)
# 将找到的点作为新的质心,加入质心数组中
new_centroid = dataSet[np.argmax(dist), :]
centroids.append(new_centroid)
return np.array(centroids)
|
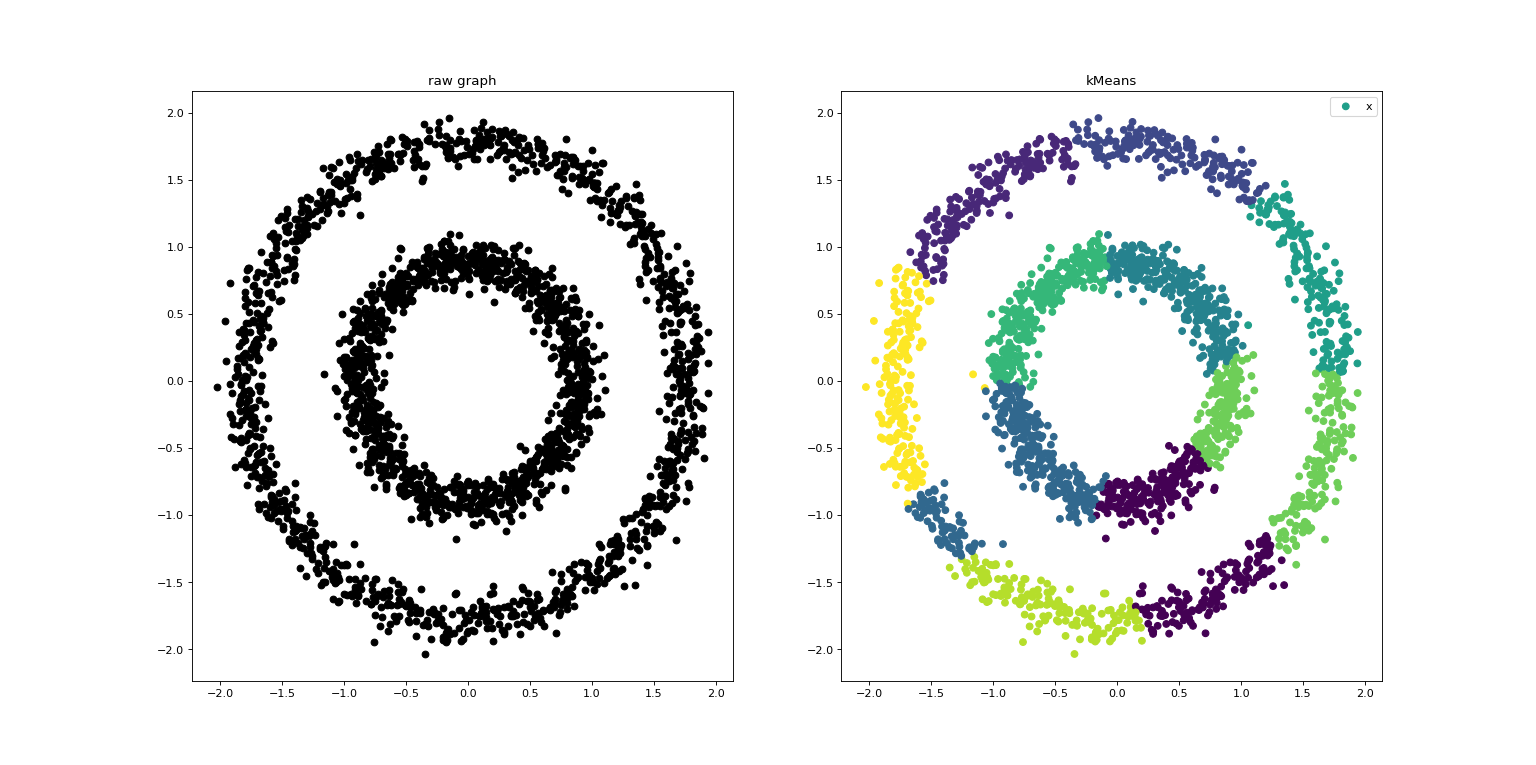
运行结果
2.4.DBSCAN算法的实现
DBSCAN是一种简单、有效的基于密度的聚类算法。
前置知识:核心点、边界点、噪声点的定义

DBSCAN算法伪代码
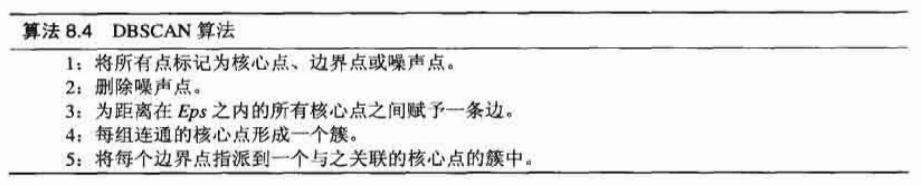
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
def get_domain_point_mat(data_set, eps):
# 获取距离矩阵
distance_mat = get_distance_mat(data_set)
# 所有点的方阵,在领域内为1,不在为0
domain_point_mat = (eps > distance_mat).astype(int)
return domain_point_mat
def get_nearest_core_point(data_set, core_points, border_points):
# 获取距离矩阵
distance_mat = get_distance_mat(data_set)
# 选择子矩阵,边界点到核心点距离的
temp_mat = distance_mat[border_points, :]
result_mat = temp_mat[:, core_points]
border_nearest_core_points = np.argmin(result_mat, axis=1)
return border_nearest_core_points
# 请补全
def dbscan(data_set, eps, min_pts):
"""
DBSCAN聚类算法,返回每个样本的cluster类别
"""
m = data_set.shape[0] # 获取样本数量
# 簇类别数组,未分类的点标记为-1
cluster = np.full(m, -1)
# 区别核心点,边界点,噪声点,噪声点类别分为-1
domain_point_mat = get_domain_point_mat(data_set, eps) # 获得的点的邻接矩阵,1表示在领域内,0反之
core_points_idx = np.nonzero(np.sum(domain_point_mat, axis=1) >= min_pts)[0] # 找到核心点索引
not_noise_point = np.nonzero(np.sum(domain_point_mat[core_points_idx], axis=0))[0] # 边界点和核心点的集合
border_point = list(set(not_noise_point) - set(core_points_idx))
# 将距离为eps之内的所有核心点赋予一条边,每组连同的核心点形成一个簇
new_cluster_label = 0
unallocated_core_point = set(core_points_idx.copy())
while len(unallocated_core_point) > 0:
start_point = unallocated_core_point.pop() # 未分配核心点数组的第一个作为类似广度优先搜索的起始点
new_cluster = set([start_point])
allocated_core_point = []
# 由start_point开始寻找新的一个连通分支
while len(new_cluster) > 0:
point = new_cluster.pop()
cluster[point] = new_cluster_label
allocated_core_point.append(point)
adjc_points = np.nonzero(domain_point_mat[point, :])[0]
adjc_core_points = set(adjc_points) & set(core_points_idx) - set(allocated_core_point)
new_cluster = new_cluster | adjc_core_points
new_cluster_label += 1
unallocated_core_point = unallocated_core_point - set(allocated_core_point) # 更新未分配核心点的集合
# 分配边界点,将边界点分配到最邻近的核心点
core_nearest = get_nearest_core_point(data_set, core_points_idx, border_point) # 获取边界点最近核心点的索引,这个索引是对于核心点数组而言的
for border_p in range(len(border_point)):
cluster[border_point[border_p]] = cluster[core_points_idx[core_nearest[border_p]]]
return cluster
|
运行示例
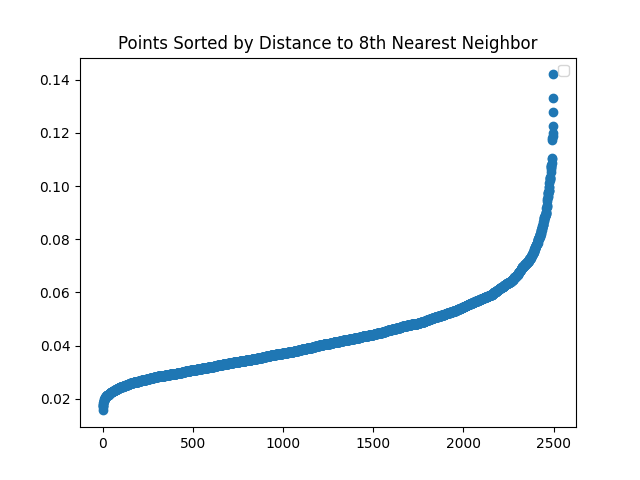
K-距离图:所有点到其第k个最邻近点的距离排序(从小到大),横轴为排序后点的索引,从0 ~ m-1(m为数据点的数量),纵轴为点到第k个最邻近点的距离。
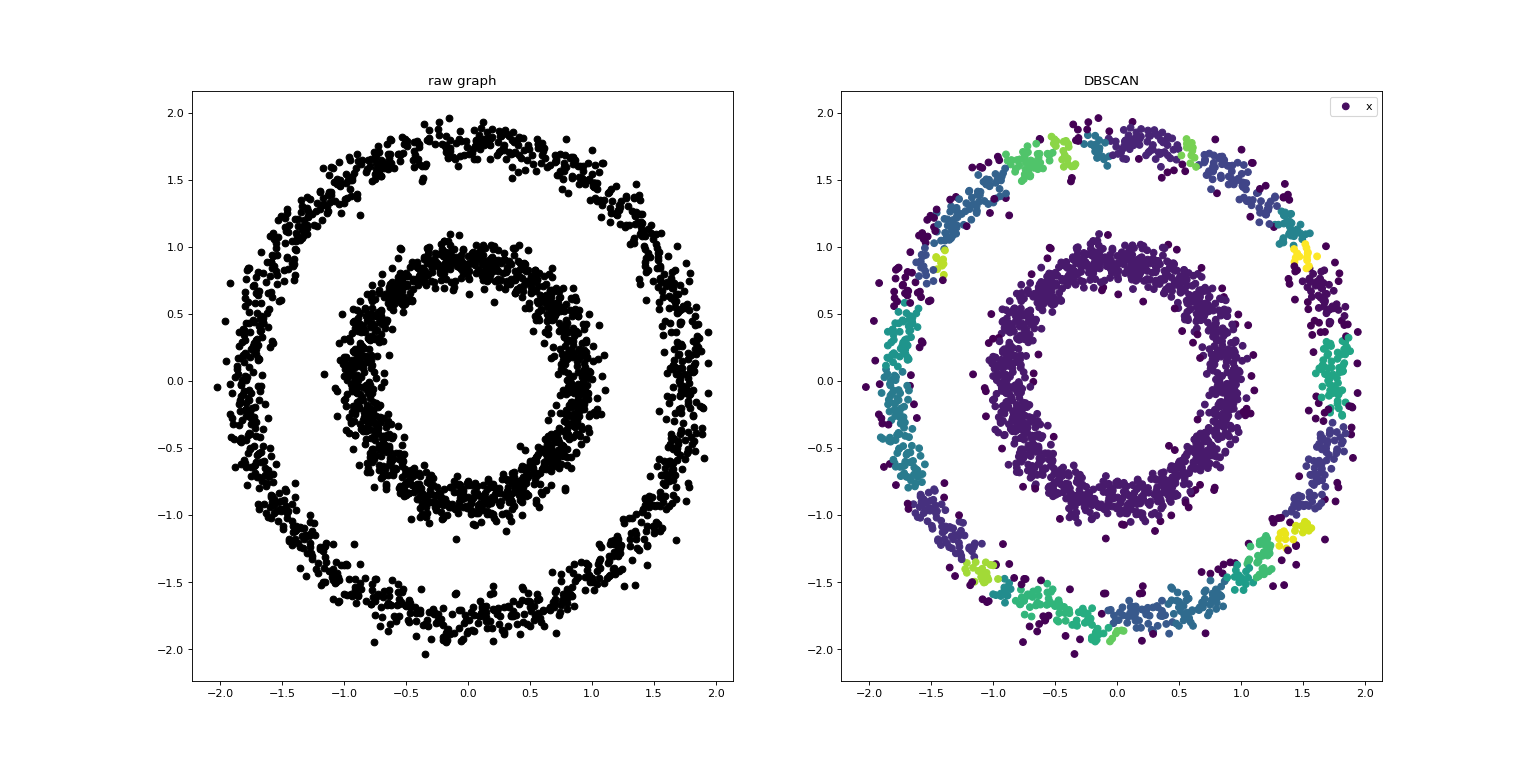
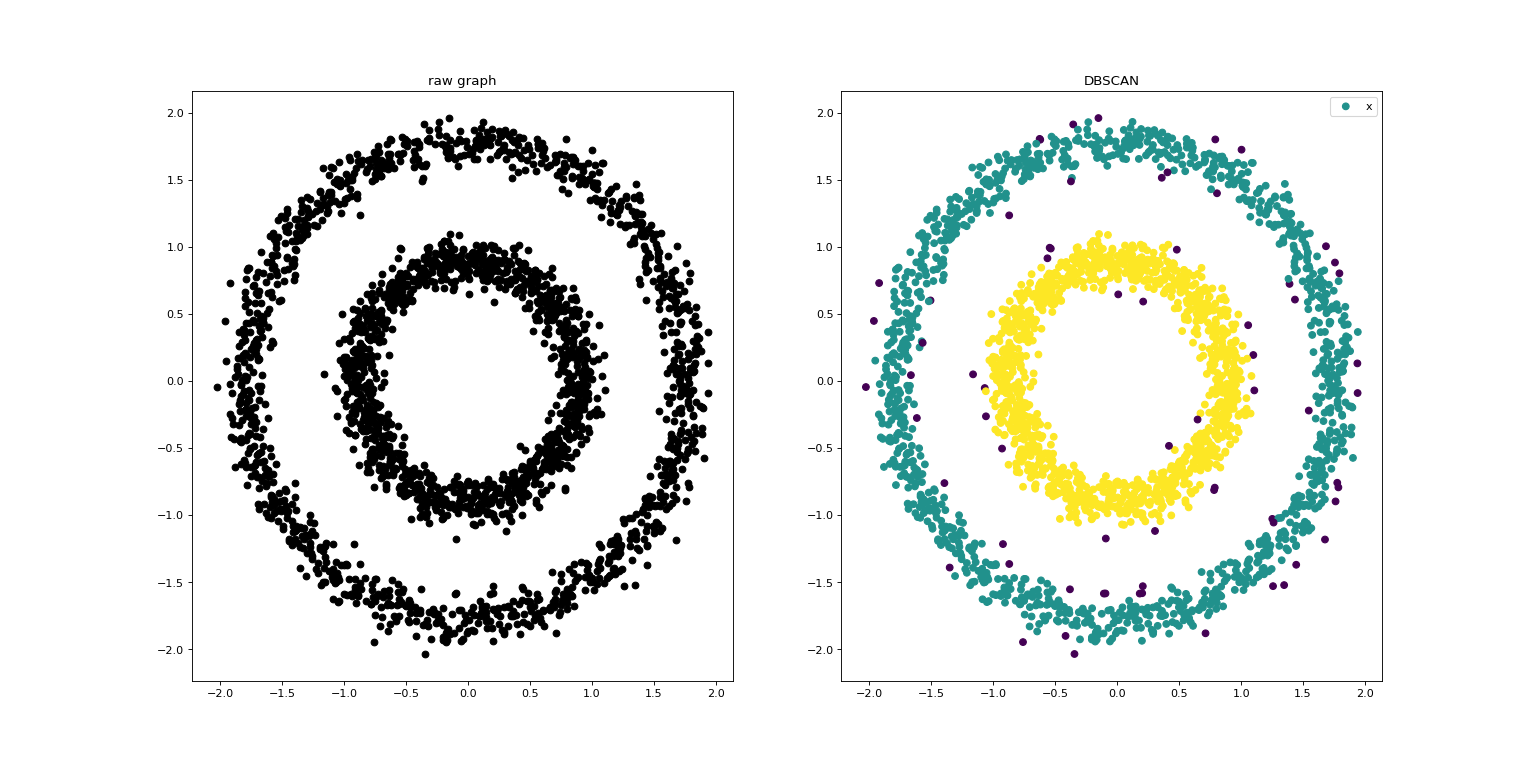
参考资料
- 数据挖掘导论(完整版)Pang-Ning Tan等主编
- 《数据挖掘》课程实验一