逻辑回归的损失函数
逻辑回归的损失函数通常是通过最大似然估计(Maximum Likelihood Estimation, MLE)推导得到的,最大似然估计介绍如下:
最大似然估计(Maximum Likelihood Estimation, MLE)是统计学和机器学习中一种常用的参数估计方法,用于估计模型参数以最大化观测数据的似然函数。
最大似然估计: 让我们通过一个生动的例子来解释最大似然估计(Maximum Likelihood Estimation,MLE)是什么。假设你是一名统计学家,对某个城市的新生儿体重感兴趣。你想估计这个城市新生儿的平均体重。
你在医院收集了 100 个新生儿的体重数据。这些数据如下:
- 2.7 kg
- 3.1 kg
- 2.9 kg
- 3.4 kg
- …
现在,你知道新生儿的体重通常服从正态分布(高斯分布)。你的任务是使用这些观测数据来估计这个城市新生儿的平均体重。
这就是应用最大似然估计的场景。你首先要选择一个概率分布模型,正态分布是一个合适的选择,因为它通常用于描述连续型随机变量,如体重。正态分布由两个参数描述:均值(平均值)和标准差。
你的目标是找到最适合数据的均值和标准差,以使观测数据出现的概率最大。这就是似然性的概念。似然性表示给定模型参数的情况下,观测数据出现的概率。
你可以使用最大似然估计来估计这两个参数,即找到均值和标准差,以使似然性最大化。在这个过程中,你会考虑所有观测数据,并寻找能够最好描述这些数据的模型参数。
一旦最大似然估计完成,你将得到一个估计的均值和标准差,这些值代表了这个城市新生儿的平均体重和体重分布的变异程度。
通过最大似然估计,你将以一种统计上合理的方式估计这个城市新生儿的平均体重,这是一种常用的参数估计方法,可用于许多不同的统计和机器学习问题。
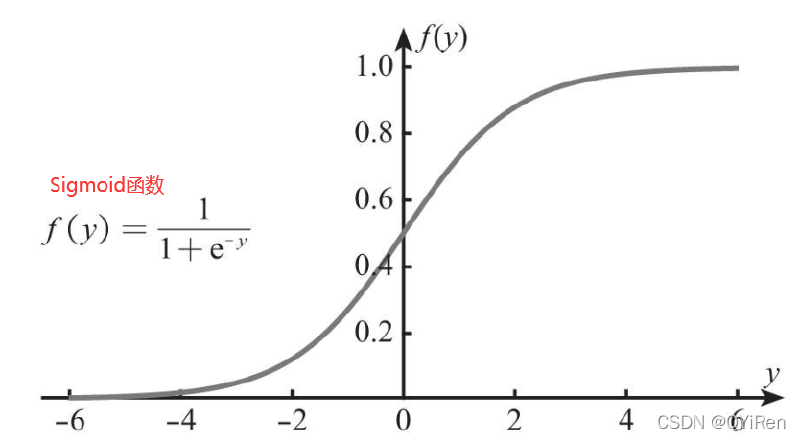
sigmoid 函数: 这是逻辑回归中的激活函数,用于将线性组合的特征和权重映射到 (0, 1) 之间的概率值。sigmoid 函数的定义如下:
$$sigmoid = \frac{1}{1 + e^{-x}}$$
|
|
计算逻辑回归损失的函数
为什么逻辑回归可以使用最大似然估计:
-
概率建模:逻辑回归是一种概率模型,它使用 logistic 函数(sigmoid 函数)将线性组合的特征和权重映射到一个介于 0 和 1 之间的概率值。对于二元分类问题,逻辑回归建模了样本属于正类别的概率
P(y=1)。 -
对数似然函数:在逻辑回归中,对数似然函数用来描述观测数据的似然性。对数似然函数是根据样本的实际类别(
y)以及模型的预测概率(hx)来构建的。具体来说,如果y=1,对数似然函数是log(hx);如果y=0,对数似然函数是log(1 - hx)。 -
最大化似然函数:逻辑回归通过选择模型参数
theta,使对数似然函数最大化,从而最大化似然性。这意味着模型的参数将被调整以使其与观测数据的概率分布最匹配,即最大程度地与数据一致。 -
最小化损失函数:通常,为了求解最大似然估计,我们会取对数似然函数的负数,以将最大化问题转化为最小化问题。这就是逻辑回归中的损失函数,通常表示为:
$$L = -\frac{1}{N}\sum_{i=1}^{N} \left[y_i \log(hx) + (1 - y_i) \log(1 - hx)\right]$$
其中,$L$ 是损失函数,$N$ 是样本数量,$\sum$ 表示对所有样本求和, $y_i$ 是第$i$个样本实际观测值。
下面是当正类为1,负类为-1的逻辑回归函数计算方式
|
|
逻辑回归梯度函数的推导
逻辑回归的梯度可以通过最大似然估计(Maximum Likelihood Estimation, MLE)的方法来推导。下面是逻辑回归梯度的推导:
假设我们有一个二元分类问题,标签 y 取值为 0 或 1,而模型的输出是一个概率值,通常用 Sigmoid 函数来表示,即 $$hx = \frac{1}{1 + e^{-z}}$$,其中 $z$ 是线性组合($z = X\theta$)。
逻辑回归的目标是估计模型参数 theta,以使模型的预测概率 $hx$ 与实际标签 y 尽可能一致。逻辑回归的损失函数通常使用对数损失函数(log loss)来衡量模型的性能。
对数损失函数的定义如下:
- 如果 $y=1$,对数损失函数为 $-log(hx)$
- 如果 $y=0$,对数损失函数为 $-log(1 - hx)$
现在,我们将计算损失函数相对于模型参数 $\theta$ 的梯度。对于一个训练样本,梯度的计算如下:
-
如果 $y=1$,对数损失函数为 $-log(hx)$。使用链式法则,我们可以计算关于 theta 的偏导数:
$$\frac{\partial(-log(hx))}{\partial \theta} = -\frac{1}{hx} * \frac{\partial {hx}}{\partial \theta}$$
其中 $\frac{\partial {hx}}{\partial \theta}$ 表示 $hx$ 相对于 $\theta$ 的偏导数。我们知道 $hx = \frac{1}{1 + e^{-z}}$,因此:
$$\frac{\partial {hx}}{\partial \theta} = \frac {e^{-z}} { (1 + e^{-z})^2} * {\frac{\partial z}{\partial \theta}}$$
-
如果 $y=0$,对数损失函数为 $-log(1 - hx)$。同样使用链式法则,我们计算关于 theta 的偏导数:
$$\frac{\partial {(-log(1 - hx))}}{\partial \theta} = -\frac{1}{1 - hx} * \frac{\partial{(1 - hx)}}{\partial \theta}$$
由于 $1 - hx = 1 - \frac{1}{1 + e^{-z}}$,我们可以计算 $\frac{\partial{(1 - hx)}}{\partial \theta}$:
$$ \frac{\partial{(1 - hx)}}{\partial \theta} = -\frac {e^{-z}} { (1 + e^{-z})^2} * {\frac{\partial z}{\partial \theta}}$$
-
将上述两种情况合并,我们得到逻辑回归损失函数相对于 $\theta$ 的梯度:
$$\nabla L_{\theta} = (-\frac{y}{hx} + \frac{1 - y}{1 - hx}) * \frac{e^{-z}} {(1 + e^{-z})^2} * \frac{\partial z}{\partial \theta}$$
简化后:
$$\nabla L_{\theta} = (hx - y)X$$
支持向量机
支持向量机(Support Vector Machine,SVM)是一种强大的监督学习算法,主要用于分类和回归问题。它在许多应用领域中都表现出色,如文本分类、图像识别、生物信息学等。SVM的原理涉及到最大间隔分类和核技巧,以下是对SVM的详细介绍:
1. SVM的基本思想:
SVM的核心思想是找到一个最佳的超平面(或线性决策边界),以将数据点划分成不同的类别。这个超平面被选为可以最大化类别之间的间隔,因此SVM也被称为最大间隔分类器。SVM的目标是找到一个决策边界,使得两个不同类别的样本离这个边界的距离最大。
2. 最大间隔分类:
SVM寻找一个超平面,该超平面能够将不同类别的样本分开,并且使这两个类别最近的样本点到超平面的距离尽可能远。这两个最近的样本点被称为支持向量,它们决定了超平面的位置和方向。SVM的目标是最大化支持向量到超平面的间隔,这被称为最大间隔分类。
3. SVM的优化问题:
SVM的任务可以表述为一个凸优化问题。给定训练样本集,SVM的目标是最小化损失函数,其中包含两部分:
- 惩罚项(正则化项):用于控制模型复杂度,防止过拟合。
- 合页损失项:用于确保样本点距离超平面的间隔足够大。
这个优化问题通常形式为二次规划(Quadratic Programming),可以使用优化算法(如SMO、梯度下降等)来解决。
4. 核技巧(Kernel Trick):
SVM还引入了核技巧,允许SVM在高维特征空间中进行非线性分类。核技巧可以将原始特征映射到更高维的特征空间,从而使数据在新的特征空间中线性可分。常见的核函数包括线性核、多项式核、径向基函数(RBF)核等。内核函数可以看作是一种相似性度量,它度量了两个数据点在高维特征空间中的相似程度。
5. SVM的分类和回归:
SVM最常见的应用是二元分类问题,但它也可以扩展到多类分类问题。此外,SVM也可以用于回归问题,称为支持向量回归(Support Vector Regression,SVR),其原理类似,但目标是拟合一个回归曲线,使支持向量到回归曲线的距离尽可能小。
6. 优点和缺点:
SVM的优点包括能够处理高维数据,对小样本数据效果好,支持非线性分类,以及具有很强的泛化能力。然而,SVM的计算复杂性较高,对大规模数据和高维数据的处理需要谨慎。此外,选择合适的核函数和调整超参数也可能需要一些经验和实验。
总之,支持向量机是一种强大的机器学习算法,主要用于二元分类和回归问题。它的原理基于最大间隔分类和核技巧,使其在许多应用领域中表现出色。通过合适的参数调整和特征工程,SVM可以构建出强大的分类器和回归模型。
合页损失(hinge loss)
合页损失(Hinge Loss)是支持向量机(SVM)中常用的损失函数,用于最大间隔分类。合页损失的主要目标是使正确分类的样本的预测分数远离分类决策边界,同时确保错误分类的样本的预测分数尽可能接近分类边界。
合页损失的构成:
合页损失通常由两部分组成:
-
合页损失项(Hinge Loss Term): 这一部分用于衡量模型对数据点的分类情况。对于一个样本,假设它的真实标签为 y(通常是 -1 或 1),而模型的预测值为 X.dot(theta),其中 X 是特征向量,theta 是模型参数(权重)。合页损失项的公式如下:
1loss = max(0, 1 - y * X.dot(theta))这个公式表示了真实标签 y 与模型预测之间的差距。如果差距小于1,损失为0;如果差距大于1,损失随着差距的增加线性增加。
- y 是样本的真实标签,可以是+1或-1,表示两个不同的类别。
- f(x) 是模型对样本 x 的预测分数,通常是一个线性函数。 在这个公式中,如果 y * f(x) 大于或等于1,合页损失将为0,表示正确分类。如果 y * f(x) 小于1,合页损失将是正数,表示错误分类,且错误分类的程度与 y * f(x) 与1之间的差距成正比。
-
正则化项(Regularization Term): 这一部分用于控制模型的复杂度,防止过拟合。通常使用 L2 正则化,它是模型参数 theta 的平方和除以2,如下:
1reg = (1/2) * sum(theta^2)正则化项有助于使模型的参数保持较小的值,以防止过度拟合。
合页损失的作用:
-
分类器边界确定: 合页损失用于确定SVM的分类器边界,即找到一个能够将不同类别的数据点分开的超平面。在训练中,SVM的目标是最小化合页损失项,这使得分类边界能够尽可能远离不同类别的数据点。
-
支持向量确定: 合页损失也有助于确定支持向量,这些是距离分类边界最近的数据点。这些支持向量对SVM的分类决策起关键作用,它们帮助确定分类边界的位置。
-
平衡间隔与错误: 合页损失在SVM的训练中平衡了最大间隔分类和分类错误之间的权衡。它惩罚了那些被错误分类的样本,并鼓励最大间隔分类。
参数 t 的作用:
参数 t 通常用于平衡合页损失项和正则化项的相对重要性。t 控制了损失项和正则化项之间的权重。增加 t 的值会加大合页损失项的重要性,可能导致更强烈地对分类边界进行优化,但也可能增加过拟合的风险。减小 t 的值则相反。 t 的选择通常需要根据特定问题和数据进行调整。
示例代码
|
|
合页损失梯度下降函数
python代码实现
|
|
现在,我们来推导梯度:
合页损失项贡献的梯度
首先,计算合页损失项对模型输出的梯度,L(y, f(x)) = max(0, 1 - y * f(x)),即 $L$ 对 $f(x)$ 的梯度。合页损失是一个分段函数,它在 $1 - y * f(x)$ 大于零时梯度为 $-y$,否则梯度为零。
$$ \frac{dL}{df(x)} = \begin{cases} -y & \text{if } 1 - y * f(x) > 0 \ 0 & \text{otherwise } \end{cases} $$
接下来,我们需要计算 $f(x)$ 对模型参数 $\theta$ 的梯度。因为$f(x) = X^T \theta$,所以:
$$\frac{df(x)}{d\theta} = X$$
- 现在,我们可以计算合页损失对 $\theta$ 的梯度,如果 $1 - y * f(x) > 0$: $$\frac{dL}{d\theta} = \frac{dL}{df(x)} * \frac{df(x)}{d\theta} = -y * X$$ 否则 $$\frac{dL}{d\theta} = 0$$
正则化项贡献的梯度
最后,我们需要添加正则化项的梯度,以减小权重参数的幅度,防止过拟合。
$${hinge\_loss} = t * loss + reg$$ 如果 $1 - y * f(x) > 0$: $$\frac{d({hinge\_loss})}{d\theta} = -t * y * X + \theta$$,否则 $$\frac{d({hinge\_loss})}{d\theta} = \theta$$
为了让梯度下降更稳定,通常还会单独处理截距项(theta[-1]),将其从梯度中减去,以防止截距项被正则化。这是因为截距项通常不需要正则化。
其中,这一部分是为了处理正则化的截距项。在梯度下降中,通常不对截距项进行正则化,因此这一步减去了正则化项中截距项的影响。
代码示例
|
|
Adam优化方法
Adam(Adaptive Moment Estimation)是一种自适应学习率的优化算法,通常用于训练神经网络和深度学习模型。它结合了RMSprop(Root Mean Square Propagation)和动量(momentum)方法的优点,以有效地调整学习率,并且可以适应不同参数的不同学习速度。
以下是Adam优化方法的详细介绍:
-
动量(Momentum):Adam引入了动量的概念,类似于随机梯度下降中的动量项。它帮助加速梯度下降的过程,尤其在曲线陡峭或弯曲的区域,能够减小学习的波动。
-
自适应学习率:Adam调整每个参数的学习率,根据其历史梯度信息来自适应地更新学习率。这意味着对于不同参数,学习率可以自动缩放,从而更好地适应不同参数的特性。
-
RMSprop:Adam中包含了RMSprop的思想,它使用了指数移动平均来估计梯度的二阶矩,以便自适应地调整每个参数的学习率。这有助于减小在峡谷区域的学习率,以避免震荡。
-
Bias-Correction:由于Adam的学习率和移动平均都初始化为零,可能会在初始阶段有较大的偏差。为了纠正这一问题,Adam引入了偏差修正项,确保在开始时有更稳定的学习。
-
参数更新:Adam的参数更新规则如下:
- 计算梯度:使用当前的小批量训练数据计算梯度。
- 计算动量:更新动量项,考虑历史梯度信息。
- 计算RMSprop项:更新历史梯度的平方项。
- 更新参数:结合动量和RMSprop项,以及学习率来更新模型参数。
- 应用偏差修正:应用偏差修正项以纠正参数更新。
Adam在训练深度神经网络时通常能够更快地收敛,因为它具有自适应的学习率和动量控制。然而,对于不同的问题和数据集,最佳的优化算法可能会有所不同,因此在实践中通常需要尝试不同的优化算法以找到最佳性能。
以下是Adam在随机梯度下降中的基本实现步骤:
-
初始化参数:
- 学习率(learning rate): 通常设置为一个较小的正数,例如0.001。
- 梯度一阶矩估计(momentum): 初始化为0。
- 梯度二阶矩估计(RMSProp): 初始化为0。
-
在每次迭代中,对于每个小批量样本: a. 计算该小批量的梯度。
b. 更新梯度一阶矩估计(momentum):
- 使用指数加权平均更新一阶矩估计。这类似于随机梯度下降中的动量更新。
- 具体更新规则:momentum = beta1 * momentum + (1 - beta1) * gradient
c. 更新梯度二阶矩估计(RMSProp):
- 使用指数加权平均更新二阶矩估计。
- 具体更新规则:squared_momentum = beta2 * squared_momentum + (1 - beta2) * (gradient ** 2)
d. 修正一阶矩估计偏差(bias correction):
- 随着时间的推移,一阶矩估计和二阶矩估计可能会偏向零。因此,需要进行偏差修正以获得更准确的估计。
- 具体修正规则:bias_corrected_momentum = momentum / (1 - beta1^t),其中t表示迭代次数。
e. 修正二阶矩估计偏差(bias correction):
- 具体修正规则:bias_corrected_squared_momentum = squared_momentum / (1 - beta2^t)
f. 更新模型参数:
- 使用修正后的一阶矩估计和二阶矩估计来计算参数更新。
- 具体更新规则:parameter = parameter - learning_rate * bias_corrected_momentum / (sqrt(bias_corrected_squared_momentum) + epsilon),epsilon是一个小正数,用于防止分母为零。
-
重复步骤2,直到达到停止条件(例如,达到最大迭代次数或损失函数收敛)。
总之,Adam算法在随机梯度下降中结合了动量和RMSProp,使学习率自适应地调整,以更好地适应不同参数的更新情况。这有助于提高训练的稳定性和收敛速度。